《分布式缓存-原理、架构及Go语言实现》
书籍参考代码stuarthu/go-implement-your-cache-server
本文中所有代码均为基于Go语言的逻辑代码,仅为说明逻辑意义使用,非实际项目代码
第一部分:基本功能
一、基于HTTP的内存缓存服务
1.1 Go语言实现
通过暴露HTTP/Rest接口实现对内存的缓存数据map增删改查
|
|
1.2 与Redis对比
Redis持久化方案对比
| 方案 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| RDB | 全量的缓存快照 | 压缩、性能影响小、方便备份和恢复、不占用服务进程的磁盘IO | 死机丢失数据多、执行RDB写入时响应慢 |
| AOF | 增量式保存保存所有写操作(只允许写入) | 较少的数据丢失,数据恢复 | 占用磁盘空间大、AOF比RDB速度慢(较多的磁盘IO) |
Redis-beachmark
Redis-beachmark是Redis服务自带的性能测试工具,参数包括【并发客户端数、发起请求总数、数据长度、键的取值范围、pipline长度以及测试的类型(get/set)】
对比结果
使用自实现的cache-beachmark测试inMemoryCache对比redis-beachmark测试Redis,对比结果
Redis的rps(requests per second)大概是基于HTTP内存缓存服务的4倍:性能问题主要在于REST协议的解析。
二、基于TCP的内存缓存服务
2.1 协议描述规范:ABNF
扩充巴科斯-瑙尔范式(ABNF):一种基于巴科斯范式(BNF: Backus-Naur Form 的缩写)的拓展协议描述规范,基本格式规则 = 定义 ; 注释 CR LF,例如HTTP协议的ABNF表达式:
|
|
定义整体数据解构,并从后续定义每个部分的数据格式
2.2 基于TCP的缓存协议规范
|
|
解读:整体为一个操作类型接键或键值对
| 操作 | 说明 | 请求协议 | 实例 |
|---|---|---|---|
| SET | 设置值 | S<klen><SP><vlen><SP><key><value> |
S4 6 namewangwu |
| GET | 获取值 | G<klen><SP><key> |
G4 name |
| DEL | 删除键 | D<klen><SP><key> |
D4 name |
| 错误响应 | -<elen><err> |
-8NOTFOUND |
|
| 正常响应 | <vlen><value> |
6wangwu |
2.3 Go语言实现
根据协议读取数据,并响应执行结果,如果出错则中断TCP链接
使用cach-beanchmark测试基于TCP的缓存服务是基于HTTP的2倍
三、基于RocksDB数据持久化
3.1 Go语言本地调用机制:CGO
Go语言提供的机制,可用于调用C的API函数,类似于Java语言提供的JNI等,例如
|
|
3.2 RocksDB
Facebook基于LevelDB完全使用C++开发,可以在纯内存、闪存、机械硬盘或HDFS等环境使用
Github地址:facebook/rocksdb
3.3 Go语言实现
通过cgo调用RocksDB的库文件实现对RocksDB的读写
需要注意Go自动GC,而C++需要手动管理内存,例如
|
|
第二部分:性能部分
四、用pipelining加速性能
4.1 pipelining原理
在不改变服务端实现的情况下,加速客户端性能
| 方式 | N请求耗时 | 简介 | |
|---|---|---|---|
| no pipelining | N*SRP | N个请求逐个完成 | |
| pipelining | R+S+N*P | 一次发送所有请求,服务端逐个处理并响应 |
SRT:(send retrun process,也有做RTT(round-trip time)),一个完整的请求耗时,包含发送、返回和处理耗时

4.2 拓展阅读:HTTP中的pipelining
HTTP/1.0中链接无状态、无法复用,HTTP/1.1以后支持pipelining
- 只有幂等请求(GET/HEAD)能使用pipelining,非幂等请求(例如POST)不能使用
- 请求必须依次返回,遵循FIFO,导致后续请求被阻塞
- 绝大多数http代理服务器不支持pipelining
- 和不支持pipelining的老服务器协商有问题
HTTP/2协议定义更接近TCP,通过StreamID进行流控制,从而解决HTTP/1.1中必须顺序返回的问题
4.3 Redis中的pipelining
一次请求/响应服务器能实现处理新的请求,即使旧请求还未被响应。这样即可将多个命令发送到服务器,而不用等待响应,最后在一个步骤中读取该响应。即管道(pipelining),许多POP3协议支持该功能,大大加快从服务器下载新邮件的过程。
例如使用nc进行TCP请求
|
|
也可以使用redis-beachmark的-P参数指定pipeline长度来实现该redis的pipelining功能测试
4.4 Go语言实现
服务端循环执行命令解析,并顺序写入响应结果
|
|
或则通过分离读取和写入实现异步读取和写入
|
|
这种实现是命令阻塞式的
五、批量写入
5.1 批量写入提升性能原理
pipelining从客户端角度提升性能,批量写入从服务端角度提升性能
将收到的写入请求积攒起来一次写入,提升效率体现在如下三个方面
- 减少磁盘寻道和旋转延时提升磁盘IO效率
- 写入内容放到连续内存减少CPU载入的次数和CPU内多级缓存失效
- 缓存的Set操作现在可以尽快返回而步兵等待磁盘操作结果
批量写入的缺点:
- 不再可以知晓每一次缓存Set操作的真实结果,无法细分操作的错误
- Set操作还在执行队列而未实际缓存就被访问
5.2 Go语言实现
两种方式触发批量写入,命令队列或则定时器,如果从队列中读取到或定时器触发且有待写入的,则执行批量写入
|
|
六、异步操作
6.1 批量读取的可能性
RocksDB提供了批量读取(MultiGet)的功能,但受限于如下原因在API层面和是否批量没有太大差别
- 内部存储使用静态排序表SST,但批量读取的键并不跟SST顺序一致,始终需要在SST中查询每个单独的键
6.2 异步操作提升性能原理
异步处理同一个TCP连接的请求,处理完成先后顺序与开始顺序不一致,响应顺序由协议制定者确定。
- 类似HTTP/1.1处理pipelining保持先进先出
- 类似HTTP/2保持完成顺序返回
基于制定的TCP协议,采用先进先出的响应方式
6.3 Go语言实现
针对每个请求建立响应channel队列和异步响应处理结果,
- 处理每个请求异步处理得到得到返回响应channel并放到响应队列;
- 异步处理完成将结果写入对应的队列;
- 异步监听响应队列,从每个队列取出响应channel并读取响应结果并返回响应
其中1和2保证异步处理能力,3保证顺序响应先进先出
|
|
第三部分:服务集群
七、分布式缓存
7.1 集群服务的优点
集群的有点如下:
- 拓展性:集群服务的网络吞吐量和缓存容量不受单节点硬件限制
- 性价比:高端设备单节点提供服务往往弱于同价钱多台低端设备组件的集群服务
- 容错率:单节点死机损失100%,集群损失小
集群根据解构分配两种:同构集群和异构集群。
| 种类 | 说明 | 举例 |
|---|---|---|
| 同构集群 | 节点功能相同 | 对象存储集群,分为服务节点暴露接口和数据数据存储节点 |
| 异构集群 | 节点功能不同 | 读写分离的数据库集群 |
7.2 负载均衡
负载均衡指的时通过某种算法,将整体的工作负载均分到每个几点上。
负载均衡方式:客户端负载均衡、入口负载均衡(网络入口配置一台或多台负载均衡节点)、服务端负载均衡
| 负载均衡 | 实现方式 | 优缺点 |
|---|---|---|
| 入口负载均衡 | 入口配置负载均衡节点,重定请求向到服务节点 | 代价是额外的负载均衡节点和重定向开销 |
| 缓存服务集群 | 追求速度,不采用负载均衡节点,减少重定向开销 | 客户端和服务端自行实现负载均衡 |
7.3 一致性散列
负载该有哪个节点承担需要对键进行一致性散列计算获得。
| 情况 | 举例 | 操作 |
|---|---|---|
| 正常 | 客户端获得所有节点列表,并对键计算一致性散列决定访问哪一个节点 | |
| 异常 | 服务节点死机维护或新节点、客户端请求超时或连接关闭或被服务端拒绝 | 重新获取所有节点列表并重新计算一致性散列 |
散列表就是键和节点之间的映射关系,有如下的实现方式:
| 散列方式 | 实现方式 | 解读 |
|---|---|---|
| 传统散列表 | 针对key的散列值对节点总数取模决定 | 新增删除节点时大量键被映射到别的节点上,导致缓存失效 |
| 一致性散列 | 针对节点ID和键计算散列值,且算法参数中不含节点总数,参考下文 | 减少节点数量变化影响 |
| 带虚拟节点的一致性散列 | 节点数量较少时,节点的负载可能不均衡,增加虚拟对称节点来避免这个问题 | 避免节点数量较少时的数量变化导致的散列变化 |
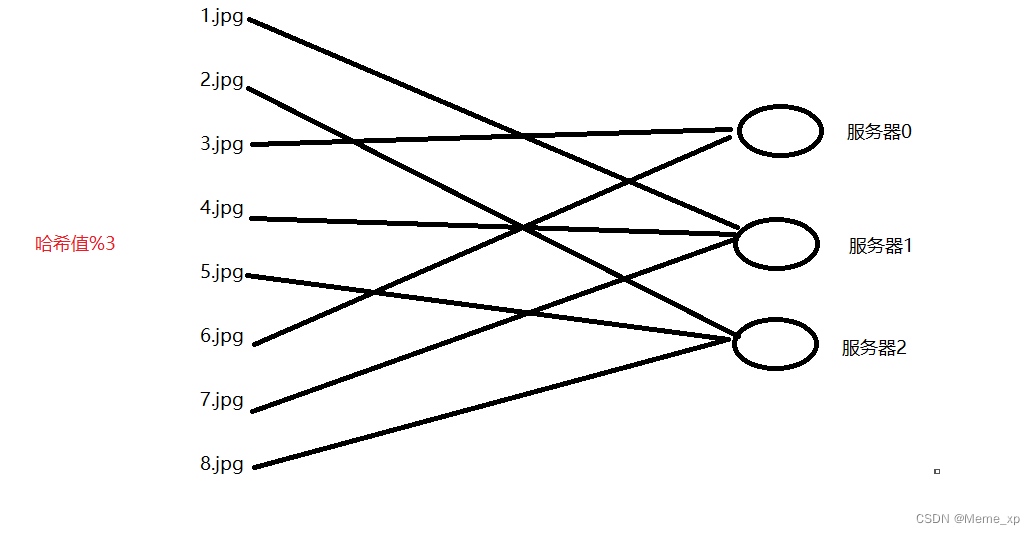
传统散列
一致性散列
一致性散列的基本实现:
- 一致性散列的实现方式可以看成一个环,也被成为散列环
- 节点ID和key一样需要进行散列计算
- 散列值计算由算法决定,不受节点总数影响
- 相邻节点的散列值决定一个半开半闭区间的范围

带对称虚拟节点的一致性散列
增加对称虚拟节点,避免节点数量少时节点的变化导致负载不均衡

7.4 Go语言实现
使用使用基于gossip协议的开源三方库
memberlist用于节点间通信;使用Go包consistent作为一致性散列库
|
|
使用配置建立节点,并将节点加入到已有集群,建立协程定时同步集群节点信息到散列环中
|
|
使用时根据节点的散列环的Get方法,传递key,判断是否由当前节点处理
|
|
八、节点再平衡
8.1 节点平衡
增删节点导致的节点缓存数据失效问题,可通过节点平衡手动同步原有缓存数据到目标节点
8.2 Go语言实现
rebalance方法通过对本节点的所有缓存键遍历,针对非本节点维护键,调用节点的缓存接口缓存对应数据并从本节点删除
|
|
九、缓存生存时间
9.1 缓存生存时间的作用
- 缓存用来提升访问网络资源的速度,并非永久存储
- 实际资源会在不知情的情况在被更新,需要提供技术进行强制缓存刷新
- 清理长时间未访问的缓存,减少缓存服务器压力
缓存生存时间就是这样一种技术,它规定了缓存自上一次被Set之后的有效期,超过有效期被认为超时并从缓存服务中被删除。
9.2 Go语言实现
缓存键值对对象增加创建时间,在新的协程中以超时时间间隔遍历所有键值对检查是否超时,如果超时则从服务器中删除该键值对
这种缓存生存时间的实现为所有键拥有相同的超时时间,如需区别可在键值对中记录超时具体超时时间或超时时长
|
|
第四部分:分布式缓存总结
非书籍内容,为个人总结
服务端端口占用情况
| 端口 | 协议 | 作用 |
|---|---|---|
| HTTP/12345 | HTTP/TCP | 缓存状态查询、集群状态查询、简单键值对增删该、集群节点平衡操作 |
| TCP/12346 | 自定/TCP | 缓存操作接口(SET、GET、DEL) |
| TCP/7946 | gossip/TCP | memberlist集群节点通信服务 |
性能优化总结
| 模块或架构 | 方式 |
|---|---|
| 客户端 | pipelining减少网络IO的时间 |
| 服务端 | 批量写入减少磁盘IO的影响、异步操作充分利用后端云算力 |
| 集群 | 节点平衡降低缓存时间频率、缓存生存时间增加数据准确性并降低服务器命中效率 |